The JaffleGaggle Story: Data Modeling for a Customer 360 View

Editor's note: In this tutorial, Donny walks through the fictional story of a SaaS company called JaffleGaggle, who needs to group their freemium individual users into company accounts (aka a customer 360 view) in order to drive their product-led growth efforts.
You can follow along with Donny's data modeling technique for identity resolution in this dbt project repo. It includes a set of demo CSV files, which you can use as dbt seeds to test Donny's project for yourself.
Before we begin: a quick note on Jaffles
If you’ve been in the sphere of dbt, you probably know the lore of the Jaffle shop. If not, I’d recommend taking a second to look at Claire Carroll’s README for the original Jaffle Shop demo project (otherwise this playbook is probably going to be a little weird, but still useful, to read).
In short, a jaffle is:
"A toasted sandwich with crimped, sealed edges. Invented in Bondi in 1949, the humble jaffle is an Australian classic. The sealed edges allow jaffle-eaters to enjoy liquid fillings inside the sandwich, which reach temperatures close to the core of the earth during cooking. Often consumed at home after a night out, the most classic filling is tinned spaghetti, while my personal favourite is leftover beef stew with melted cheese."

See above: Tasty, tasty jaffles.
Jaffle Shop is a demo repo referenced in dbt’s Getting Started Guide, and its jaffles hold a special place in the dbt community’s hearts, as well as on Data Twitter™.
So, I thought it only apt to build on the collective reverence for these tasty, crunchy snacks to talk about customer 360 views.
What's a customer 360?
A customer 360 is a fancy way of saying that you have a holistic dataset that lets understand your customers’ behavior. It involves being able to link together all of the different kinds of data you collect about customers via identity resolution, which we’ll talk through later in this tutorial.
This can be challenging because people move companies, create new accounts with different email addresses, or the same company might have different associated workspaces (gaggles 🦢 in our case).
All this to say, creating a customer 360 view is a powerful way to gain understanding of your customers and users, but can come with challenges (which we’ll help you work through).
Meet JaffleGaggle, our fictitious company
In our fictitious data world for today’s example, a B2B company saw that people really loved a thing (e.g. jaffles) and found a way to scale that beloved thing into a business. Enter JaffleGaggle.
There are two parts of JaffleGaggle’s product:
-
A feed of jaffle recipes, supported with functionality that lets you order all the ingredients you need to make late-night jaffles at home.
-
Social groups to foster bonding among a company’s teams (lovingly called a Gaggle) where coworkers can invite each other with a free email for virtual jaffle hours.
JaffleGaggle is growing rapidly and has just bought a CRM (yay!), but it’s currently empty (less yay 😟). By the end of this guide, you and the JaffleGaggle data team will know how to use dbt to model account, user, and event data from usage of their application and aggregate it into their warehouse, to upload to a CRM for use by the sales team.
As people invite more of their peers to their Gaggle, they’re able to unlock even more recipes and jaffles.
Seen above: One of the many, many delicious jaffle recipes that await teams on JaffleGaggle.
OK, now that we’ve got you hungry for some tasty, tasty jaffles, here’s what this has to do with data and product led-growth (aka PLG).
How a customer 360 view supports product-led growth
JaffleGaggle is, like many startups, focused on signing companies to annual contracts so they can raise Venture Capital funding (at an insane multiple). To do so, they want to build out their sales motion to target companies with active gaggles.
JaffleGaggle has to keep track of information about their interactions with their customers and the businesses they belong to, including data to enable to sales team to answer a few key questions:
- How has a user been interacting with the platform?
- How many workspaces are associated with a company?
- Who are the company’s power users that should be reached out to?
All of these questions require aggregating + syncing data from application usage, workspace information, and orders into the CRM for the sales team to have at their fingertips.
This aggregation process requires an analytics warehouse, as all of these things need to be synced together outside of the application database itself to incorporate other data sources (billing / events information, past touchpoints in the CRM, etc). Thus, we can create our fancy customer 360 within JaffleGaggle’s data warehouseA data warehouse is a data management system used for data storage and computing that allows for analytics activities such as transforming and sharing data., which is a standard project for a B2B company’s data team.
Diving into data modeling
In this playbook, I’ll take you along on JaffleGaggle’s journey to build a customer 360 view using dbt so they (and you, too) can supercharge their PLG strategy with better data (and spread the love of jaffles everywhere).
The data structure breaks down as follows:
- 823 gaggles
- 5,781 users (unique by email, can only be associated with one gaggle)
- 120,307 events (‘recipe_viewed’, ‘recipe_favorited’, or ‘order_placed’)
Let’s get rolling.
Builder Beware! If this was an actual event stream, it would be much better to leverage incremental models based on timestamp, but because it’s a playground project, I did not.
Step 1: Define our entities
For a freemium product like this one, where users only sign up with their email address, it’s best practice to use the email domain for users as the unique identifier for accounts. There could be multiple gaggles associated with a singular corporate email domain, thus belonging to a singular account.
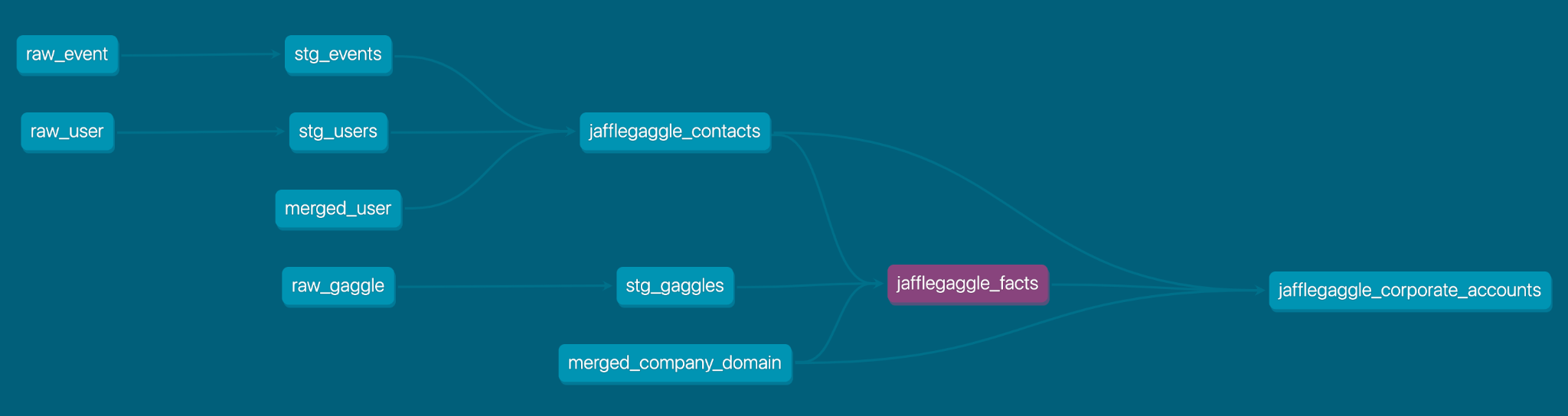
Below, I’ll break down the DAG at each step of our process so you can see how it builds all together.
To use our CRM, we’ll need to upload data for the following:
- Contacts (contacts that are unique by email address)

- Gaggles (understanding the activity of a workspace)
- Accounts (companies our sales team can track and prioritize)
Step 2: Model the contact
We’ll start at the lowest level, which are the contacts the sales team wants to reach out to, and we will then work our way up to the account. To do so, we’ll focus on three steps:
-
Performing the email domain extraction from the email
-
Flagging personal emails
-
Creating a column for corporate emails
After we complete these steps, we’ll also cover a "human in the loop" step to ensure data integrity at the modelling stage. All of this put together will help guarantee that, when contacting a user, the sales team has all of the relevant product usage information at their fingertips.
Step 2.1: Extract email domain from an email
For this step, take a look at a snippet from models/staging/stg_users.sql below. In it, we perform the email domain extraction from the email.
select
id as user_id,
name as user_name,
email,
{{ extract_email_domain('email') }} AS email_domain,
gaggle_id,
created_at
from source
We defined the email domain extraction as a macro called extract_email_domain, which we call in line 18 (which you can find in the pullout below).
This uses a regex to capture the text to the right of the ‘@’ character and makes sure to only use the lowercase email parameter before extracting the domain. This is because email domains aren’t case sensitive, but SQL is (see users 2954 and 3140 in the seed data for an example).
{% macro extract_email_domain(email) %}
{# This is the SQL to extract the email domain in the Snowflake Flavor of SQL #}
regexp_substr(lower({{ email }}), '@(.*)', 1, 1, 'e',1)
{% endmacro %}
Builder Beware! Notice we didn’t check for improperly formatted emails, like periods at the end of the domain or whitespaces. Make sure you check your dataset to see if this is a valid assumption.
Generally, it’d be useful to leverage a regular expression to strip and pull down an email address. However, because this is a B2B use case, not all email domains are created equal. We want to make sure we flag personal emails so they’re treated differently than the corporate emails our sales team will reach out to (this makes sales outreach more productive, and ensures we aren’t contacting people more than once).
Tip: If you’re building out a definition like "personal email domains" for the first time, I strongly recommend building alignment upfront with the rest of the business. . Understanding the impact and having a shared understanding of these kinds of definitions reduces friction and allows you to run your data team like a product team rather than responding to ad hoc service requests.
Step 2.2: Flag personal emails
Next, we can flag personal emails with models/jafflegaggle_contacts.sql, which calls another macro at the top of the file to pull in the personal emails we would like to exclude:
{% macro get_personal_emails() %}
{{ return(('gmail.com', 'outlook.com', 'yahoo.com', 'icloud.com', 'hotmail.com')) }}
{% endmacro %}
One of the great things about writing this as a macro in dbt is that the data team can easily reuse this file in other places in the codebase.
Doing so improves consistency and makes sure additions or deletions to this personal email list are up to date.
Step 2.3: Create a column for corporate email
Next, we’ll create a column for corporate email that will be null if an email domain is personal, also in the same jafflegaggle_contacts model:
iff(users.email_domain in {{ personal_emails }}, null, users.email_domain)
as corporate_email
Builder beware! Not all of these treatments are exhaustive. You might encounter country suffixes on email domains or other domains entirely. Be sure to check for your own use case, and add the columns that make the most sense in your scenario.
The other aspects to this users model are related to the event data we reference in the event stream. For example, the order_placed event is broken out in a CTEA Common Table Expression (CTE) is a temporary result set that can be used in a SQL query. You can use CTEs to break up complex queries into simpler blocks of code that can connect and build on each other. because it’s important to our use case at JaffleGaggle (it’s the basis for getting that dough 💰).
order_events as (
select
user_id,
min(timestamp) as first_order,
max(timestamp) as most_recent_order,
count(event_id) as number_of_orders
from events
where event_name = 'order_placed'
group by 1
),
By the end of the jafflegaggle_contacts model, we have a unified viewA view (as opposed to a table) is a defined passthrough SQL query that can be run against a database (or data warehouse). of events by user email, with personal email domains filtered out.
Step 2.4: Merging duplicate contacts
Definition: When I write "Human in the Loop" I mean that operational people at the company are contributing to data integrity at the modelling stage and reviewing data for quality. This is very important for making sure that the domain knowledge is used in the CRM definitions.
I intentionally left out two seed files, one of which data/merged_user.csv contains users the JaffleGaggle team have identified as the same person.
To track this, the team decided to track the old user email and the new user email as one. Oftentimes, in a CRM’s data schema, there’s a built-in treatment for handling merged entities.
However, since JaffleGaggle just started building out their infrastructure for a CRM, this CSV file exists to map old user emails to new (this example for Constance Rohr, userId 6759):
old_email, new_email
constancerohr@icloud.com,constancerohr@outlaws.com
So what does this do for duplicate contacts? On line 100 of jafflegaggle_contacts, we left join to that merged_user seed file to map old emails to new:
left join {{ ref('merged_user') }}
Now to generate dbt docs and view our DAG, we can run:
dbt docs generatedbt docs serve
This gives us access to the DAG for jafflegaggle_contacts.sql which can serve as the source of truth for the JaffleGaggle Ops team about where the analytics definitions live for the contacts in the system.
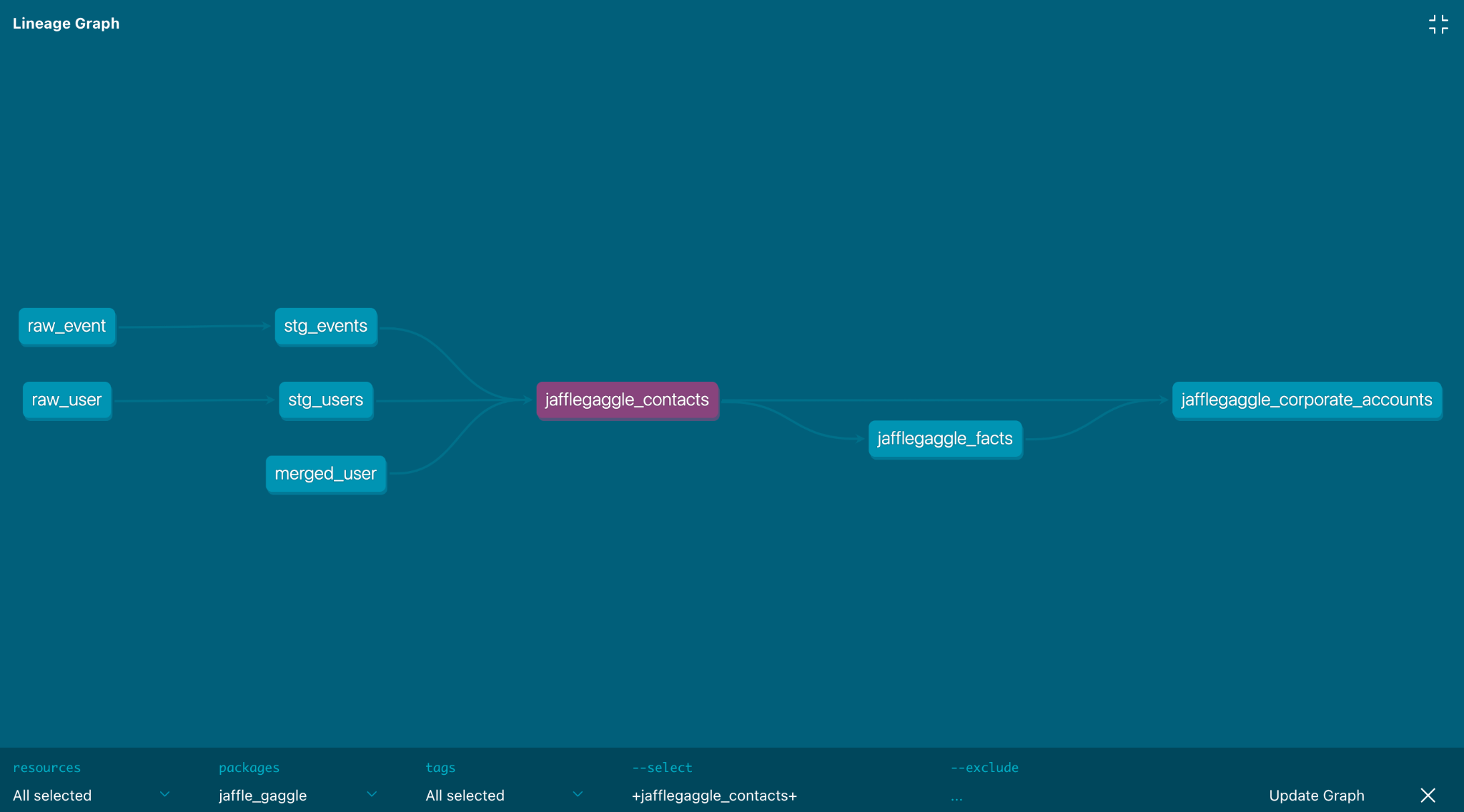
Step 3: Model the Gaggle
Working our way up to accounts, we arrive at the Gaggle, which is the traditional B2B workspace equivalent. This is important to understand how many users are associated with a workspace and when/what their activity has been.
For example, the NFL Rams (who love jaffles) moved from St. Louis to Los Angeles, changing their company email domain in the process. For the JaffleGaggle sales team, it’s important that the changed email domain does not change the identity resolution for gaggles and Accounts in the process.
If we don’t successfully do this merge when a corporate domain changes (e.g. rams.sl and rams.la), we’ll end up with two rows for the same gaggle_id (i.e. 1187), when we really just want one. The merged_company_domain seed file + a left join in the final_merged CTE of the jafflegaggle_facts model solves this problem for us.
old_email, new_email
rams.sl,rams.la
Builder beware! As is flagged in the comments of the
jafflegaggle_factsfile, this assumes that there is only one non-personal email domain per workspace. If this is not the case, we would need to establish rules for what to do among gaggles with multiple companies within, such as performing attribution to the corresponding corporate email addresses of the users within each Gaggle.
We also aggregate information on the entire Gaggle, including users who don’t have a company domain. This is found in the CTE named gaggle_total_facts.
gaggle_total_facts as (
select
gaggles.gaggle_id,
gaggles.gaggle_name,
gaggles.created_at,
min(users.first_event) as first_event,
max(users.most_recent_event) as most_recent_event,
sum(number_of_events) as number_of_events,
count(users.user_id) as number_of_users,
min(users.first_order) as first_order,
max(users.most_recent_order) as most_recent_order,
sum(users.number_of_orders) as number_of_orders
from users
left join gaggles on users.gaggle_id = gaggles.gaggle_id
group by 1,2,3
),
I know, that’s a ton of code. Check out the dbt docs for the project for an explanation of the fields. Here’s the output of final jafflegaggle_facts tableIn simplest terms, a table is the direct storage of data in rows and columns. Think excel sheet with raw values in each of the cells.:

Referring to the DAG from the dbt docs, you can see how we are already benefiting from merging at the user level for analytics information related to jafflegaggle_contacts.
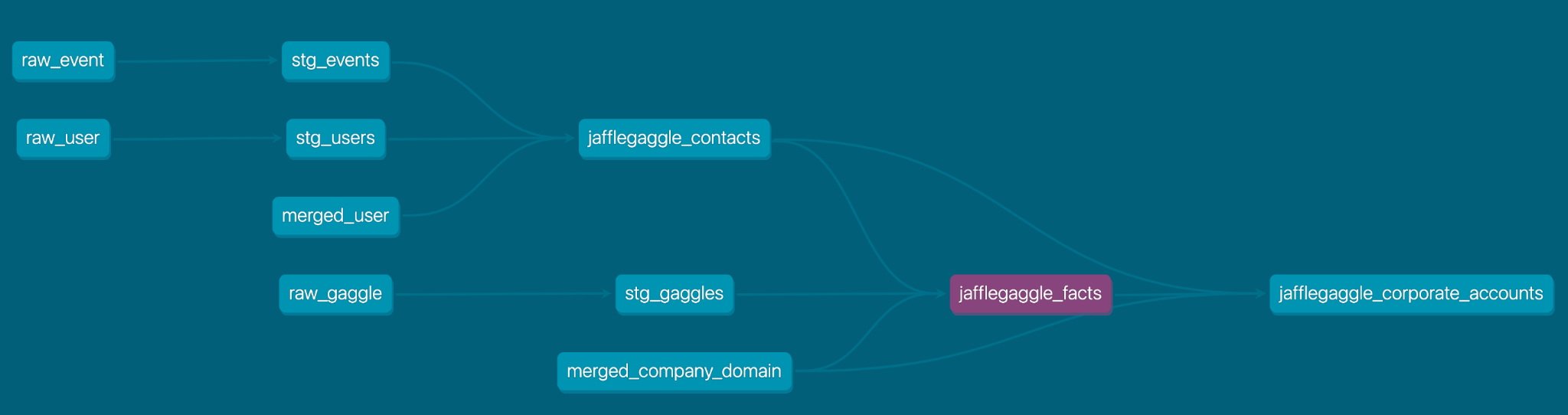
We also use an upstream table of stg_gaggles which pulls in information about the creation of the Gaggle and its name.
Step 4: Model the Account
We have modelled the contacts and the gaggles, so we are at the account level now.
We want to join the characteristics for different gaggles that share the same company email address domain so we can use operational analytics to create a customer 360 view for the sales team to prioritize outreach efforts. 🙌
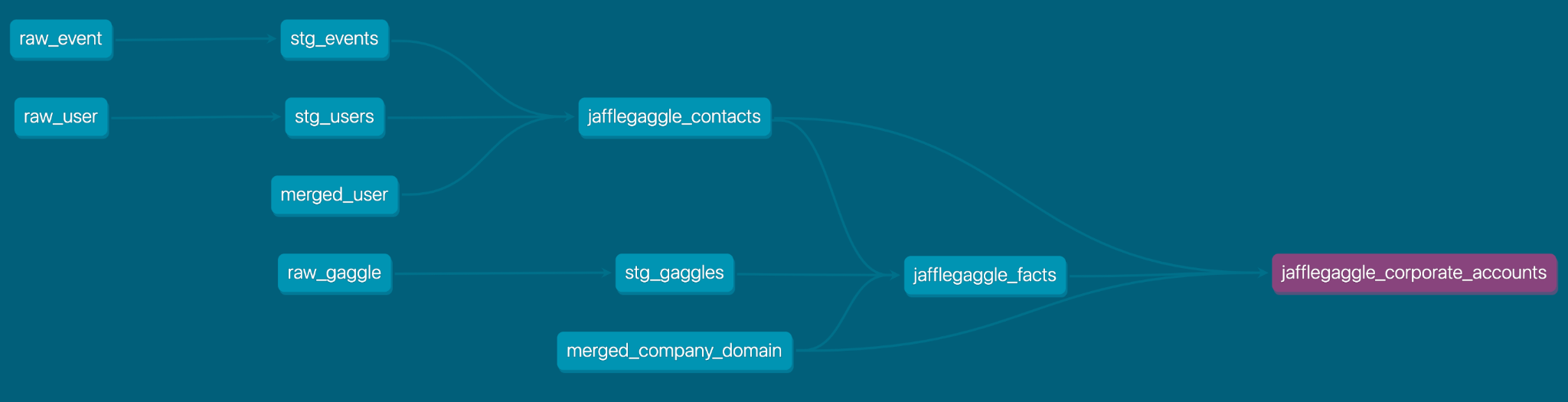
By looking at the dbt docs, we see that every model is an upstream source for jafflegaggle_corporate_accounts.
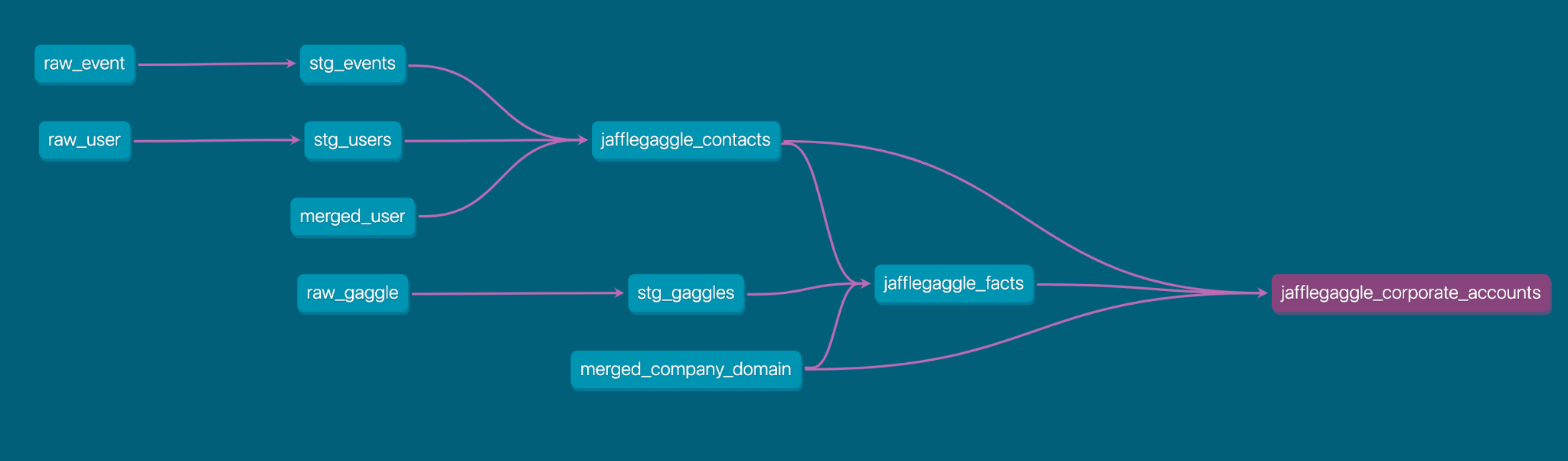
At this level we coalesce the company for the merged domain as we did with the merged_users previously. Here’s the code for this step:
select
coalesce(mcd.new_domain, corporate_gaggles.corporate_email) as corporate_email,
....
from corporate_gaggles
left join {{ ref('merged_company_domain') }} mcd on corporate_gaggles.corporate_email = mcd.old_domain
group by 1
Note: This is not the only place where we reference the merged_company_domain file. We also need to reference this in the case where there are distinct gaggles with the old and new corporate domains, such as the Thrashers and the Jets.
Here is an output of the final corporate accounts table:

Step 4.1: Identify power users for an account
Now imagine the sales operations team has identified the accounts they want to reach out to. They’ll also need to identify who they should contact to upgrade the account to paid.
Ideally, this is a jaffle-loving office manager who created the account, who has been the most active, and who has placed the most orders.
Great news for the sales team! We can identify those folks using the following CTE to identify the top users for each account.
corporate_power_users as (
select
corporate_email,
get(array_agg(user_id) within group (order by created_at asc), 0)::int as first_user_id,
get(array_agg(user_id) within group (order by number_of_events desc), 0)::int as most_active_user_id,
get(array_agg(user_id) within group (order by number_of_orders desc), 0)::int as most_orders_user_id
from {{ ref('jafflegaggle_contacts') }}
where corporate_email is not null
group by 1
),
In almost every CRM, there’s a supported Lookup functionality, which means a record includes a property linked to another related record. As long as the user_id is marked as an external and unique id for the contact object in the CRM, this can be set from the model here.
Building the JaffleGaggle empire of your dreams
Congrats! If you’ve made it this far, you should be well on your way to establishing the JaffleGaggle empire you’ve always dreamed of. Since we covered a lot of ground in this tutorial, here’s a summary of all the steps together:
-
Define your entities
-
Model the contact
-
Perform the email domain extraction from the email
-
Flag personal emails
-
Create a column for corporate emails
-
Add in your human in the loop logic
-
-
Model your Gaggle to summarize each group and aggregate that information for workspaces, or other relevant user groups.
- Add in human in the loop merging logic
-
Model your account to join the characteristics for different user groups with the same company email domain.
- Add in human in the loop merging logic
If we wanted to take it a step further we could:
- Create a model for gaggles based solely on personal emails, who might consider moving to paid
- Create another layer of breakdown that uses
user_gaggleorgaggle_domain
In terms of data architecture, there are four things you need to do to get this productionized:
- Use reverse ETL to get these fact tables synced to the CRM
- Track payment or subscription information for which accounts are currently paying
- Leverage ETLExtract, Transform, Load (ETL) is the process of first extracting data from a data source, transforming it, and then loading it into a target data warehouse./ELTExtract, Load, Transform (ELT) is the process of first extracting data from different data sources, loading it into a target data warehouse, and finally transforming it. to get CRM data back into the data warehouse
- Design for how you can extend the current merging solution

If you’ve made it this far, you’ve gone from having three raw source tables to a business-specific source of truth within your own data warehouse featuring human-in-the-loop identity resolution, email domain dbt macro magic, and best practices for operationalizing B2B product-led growth. You most definitely deserve a jaffle. 🥪
DM me in dbt Community Slack (I’m @Donny Flynn (Census)) if you want to learn more about JaffleGaggle, PLG, reverse ETL, or how I created these random datasets. 😊
PS: @clrclr don’t hate me. 🙏🏻
Comments